O que um banco de dados Armazena ?
O banco de dados armazena informações que são importantes para melhoria dos processos de negócios da empresa. Por exemplo, saber o que vendeu, o que tem no estoque, quais clientes são bons e os problemáticos, etc. Sempre o interesse de um banco de dados é melhorar os negócios e com isto a renda da empresa.
Portanto num banco de dados temos uma 'abstração' ou uma 'representação' do mundo real onde armazenamos o que precisamos saber sobre essa 'entidade' .
Um exemplo clássico é a tabelas de produtos vendidos que pode se chamar tabela 'vendas'. Portanto a tabela de vendas representa uma 'entidade' ou um 'assunto' (vendas) do mundo real no nosso banco de dados .
Mas o que precisamos armazenar da venda ? : A resposta é simples, tudo que precisaremos saber sobre a venda no futuro para melhor gerir nosso negócio. Conseguimos pensar, de imediato, em dados básico como o produto vendido, a quantidade vendida, o preço unitário...o que mais ? Pra quem foi vendido, a data que foi vendido, etc. Essas 'propriedades' ou 'atributos' de vendas seriam as colunas ou campos da tabela.
Um conjunto dessas 'colunas' são agrupadas em uma linha e essa linha, dependendo da finalidade da tabela, tem os dados que definem unicamente um item da entidade. Por exemplo, na tabela de vendas um conjunto de colunas formariam uma linha que teriam todos os dados de uma venda específica. Todas as informações sobre uma venda efetuada estaria nessa linha e as colunas teriam os campos que são fundamentais para nosso negócio, como produto, quantidade, etc...seja para contabilidade, para o faturamento, para o Follow Up de pós venda do cliente, seja para o que for importante para a empresa.
Note que uma vez definido um 'conjunto de propriedades' ou 'colunas' de uma entidade a coisa NÃO terá quer ser para sempre assim. Podemos com o andamento do processo precisar de mais um dado, por exemplo, um email de contato. Seria basicamente agregar uma coluna a linha de dados do cliente. Esses ajustes vão sendo feitos com o decorrer do tempo. Para efeito de sistemas a gente pode agregar colunas no fim da tabela e desde que ela(s) não sejam obrigatórias (not null ou outra constraint) pouco impacto causarão ao processo. Se for necessário inserir uma coluna no meio das colunas já existentes isto obrigará a revisão de todos os processos que utilizem a tabela pois um insert sem campos definidos ou se o campo contiver uma constraint precisaremos revisar todos os processos que usem a tabela pois darão erro.
Boas práticas
Se você é desenvolvedor de software já deve ter ouvido falar em boas práticas. São, basicamente, recomendações que visam padronizar o processo para um melhor entendimento por todos e ainda evitar com que sejam cometidos os erros básicos e mais comuns e com isso poupar trabalho nas etapas de correção, manutenção e desenvolvimento de processos.
Por exemplo, para que escrever a mesma coisa extensa em um monte de lugares como o nome de uma mesma pessoa se eu posso escrever o nome em apenas um lugar e usar a 'referencia' a ele sempre que necessário? Isso é possível num banco de dados e pouparia muito disco, espaço, tráfego de rede, etc.
Outro exemplo é a criação da chave primária em todas as tabelas. É uma boa porque a chave primária é a chave de melhor seletividade e seleciona apenas um registro dando certeza que um 'update' será feito apenas no item selecionado se for usado a chave primária. Mas nem sempre uma chave primária atende a pesquisa que precisamos senão não existiriam as chaves compostas ou candidatas.
Como tudo em SQL não são 'cláusulas pétreas', ou sejam, 'verdades absolutas'. Há situações em que quebrar essas regras trazem ganhos mas isso é discussão de especialistas. Novatos, via de regra, devem seguir essas regras até terem conhecimento de situações onde quebrar essas regras seria melhor.
Outra coisa que sabemos é que o SQL se dá muito bem com números, muito mais que com strings. Por isso se tiver que acrescentar um campo numérico teremos um peso mas um campo string, com certeza, será muito mais pesado pelo seu tamanho. Por exemplo, ao pesquisar um endereço teremos uma performance muito melhor se for pelo CEP da rua do que com o seu nome e não se esqueça que estamos nos referindo ao nome de rua normalizado porque o erro mais cometido em qualquer cadastro de endereços é a grafia do nome de rua errada.
Normalização
Normalização é um conjunto de regras formais, ou sejam, não são restrições físicas impostas por quesitos técnicos a uma tabela, banco de dados ou a um processo mas sim conceitos, conselhos ou regras que visam poupar erros, diminuir espaço, simplificar a classificação, melhorar processos dando rapidez e simplificando a manutenção e utilização do um banco de dados.
A Normalização foi dividida em regras e quando dizemos que o banco de dados segue a primeira regra de Normalização (1NF) significa que ela atende a essa regra. Como foi dito, as regras de normalização são dicas ou conselhos para melhorar o que está sendo feito mas não são obrigatórias. Contudo não é possível atingir, por exemplo, a segunda regra formal sem antes atingir a primeira ...elas são uma sequencia.
Um dos conceitos mais relevantes em normalização de banco de dados é a redundância, seja em uma tabela, pesquisa ou num índice. Se vou armazenar numa tabela de vendas o nome do cliente é melhor fazer um cadastro de clientes separados ou deixá-los na tabela de vendas ? Isso a empresa deve definir. O mesmo ocorre com um índice composto, por exemplo, para que vou colocar 5 campos como chaves de pesquisa num where se um só ou dois já definiria a cardinalidade de 1 para 1 ? Isto seria redundância na pesquisa e seria assunto para otimização da pesquisa.
Normalização - Primeira regra Formal - 1NF
A primeira regra define que os dados armazenados contenham apenas um valor intrinseco, ou seja, único e específico de um atributo da identidade representada.
Em termos leigos tem 2 significados. Um é que se uma tabela chama-se 'clientes' e tem um campo chamado 'nome' esse 'nome' só pode ser do 'cliente', não é o da mulher dele, do filho/filha...sem dúvida nenhuma é o nome do cliente, um uso só para toda a tabela. Digamos que o uso do campo é específico para aquela única utilidade.
O segundo significado é que se tenho um cliente todos os demais campos do registros tenham uma e apenas um valor correspondente ao cliente. Se, por exemplo, o cliente tem 2 telefones eu não vou colocar os campos 'telefone1' e 'telefone2' para armazenar as informações porque se ele tiver um terceiro telefone (digamos o comercial), onde você iria armazenar ? E se tivesse mais um ( o fax ) onde iria armazenar? E um telefone de recados onde iria armazenar. Portanto se eu tiver que armazenar o telefone ou só coloco 1 telefone ou faço um cadastro de telefone e falo que todos aqueles telefones pertence ao clientex.
Talvez ainda não tenha ficado claro, a coisa é complexa e completamente conceitual. Mas a aplicação prática desses conceitos rende eficiência em matéria de banco de dados.
Explicando melhor, se você tem um campo chamado nome não há nada que te impeça de colocar o nome do cliente, da esposa, do filho, do gato, cachorro no mesmo campo. Aparentemente o banco de dados pode armazenar isso sem problemas, um campo string pode ter uns 6000 caracteres ... sem problemas ...mas se você precisar pegar o nome do filho terá que fazer um 'algorítimo' para buscar ele e se o 'cadastrante' inverteu o nome do filho com o da esposa você obterá o dado errado e ele também pode ter omitido o nome do filho porque o casal ainda não tem filhos aí você fica sem saber exatamente de quem é o nome armazenado.
Se você criou um campo para armazenar o nome do cliente este só poderá ter o nome do cliente. Se precisar colocar o nome da esposa, filhos deverá armazenar em outro campo e seria um campo para cada um, um para o nome da esposa, um para o nome do filho, etc...nunca combinando eles no mesmo campo. Portanto o campo tem que ter um 'uso' único e restrito ao seu propósito. Não devo ter dúvidas se o nome é do cliente, da esposa, do filho.
O pior exemplo disso é o cadastro de logradouros ( ruas ). Quando o operador do sistema vai cadastrar onde o cara mora ele escreve Rua, R. ou nada e aí, como a sintaxe não é rígida você poderá ter centenas de nomes para a mesma rua. Dizemos que o cadastro de ruas não está normalizado, ou seja, não segue, sempre, uma norma.
Portanto, para seguir a primeira regra da normalização os campos devem ter valores únicos. Se uma pessoa tem 5 telefones esses telefones não poderão ser colocados em uma coluna da tabela chamada 'telefone', estaríamos repetindo um atributo para o mesmo elemento da entidade. Estaria quebrando a 1NF porque para obter o telefone seriamos obrigado a criar um algorítimo para extraí-los e, mesmo assim, não saberiamos se o primeiro é tel, o segundo o fax, o terceiro o celular, etc...Com certeza, seria melhor separá-los em campos específicos, um para cada tipo de telefone específico.
Esta regra garante que o valor obtido na pesquisa tenha unicamente a uma utilidade e tenha unicamente um significado apenas, sem dúvidas. . É o nome do cliente e acabou. Não é o nome da esposa, do filho / filha, etc.
Se a tabela é de clientes eu não deveria cadastrar informações nela que não fossem sobre o cliente em sí. Todas as informações 'extras' sobre o cliente como telefones ou ruas se forem coisas pontuais, pequenas, até podemos armazenar na tabela de clientes mas o correto poderia ser armazená-las em separado. Isto porque sabemos que são muitas e não pertencem ao cliente em sí mas sim a uma condição do cliente. Sabemos que podemos ter mais de um cliente em uma rua e por isso rua não pertence ao cliente mas sim a uma circunstância ou atributo do cliente e isto faria o banco de dados ter informações redundantes, como nomes de ruas iguais em 2 clientes diferentes.
Outro jeito de violar a 1NF seria criar colunas com a mesma utilidade. Por exemplo, para armazenar o telefone do cliente colocaríamos 4 colunas para telefones com o nome Telefone1, Telefone2, Telefone3, Telefone4. Mesmo se colocássemos nos nomes das colunas Telefone, Fax, Celular, etc. estaríamos violando a 1NF porque são colunas com a mesma utilização, armazenar o mesmo item com diversas repetições. E viola a regra porque se quiséssemos colocar um Telefone5, Telefone do serviço, Telefone de Recados teríamos que fazer uma 'adaptação' do campo o que viola o conceito de utilização única do mesmo.
Outro motivo para esta regra existir é que se uma pessoa falar que o campo tem o nome do cliente podemos assumir isso para toda a tabela. Não terá que dizer...mas se tiver um segundo nome é o nome da esposa...se tiver um terceiro é o nome do filho...e onde termina um nome e começa outro ? Evita muita complicação.
Para ser mais puritano dizemos que a 1NF é atendida sempre que armazenar um item escalar, ou seja, se é um telefone e numérico ele só armazena um telefone e um número, nunca 2 números.
Para resolver este problema poderíamos criar uma nova tabela de telefones, por exemplo, e associar o telefone ao número do cadastro do cliente. Assim, todos os telefones estariam associados ao cliente e o fato de inserir, eliminar, pesquisar os telefones do cliente não teríamos problemas.
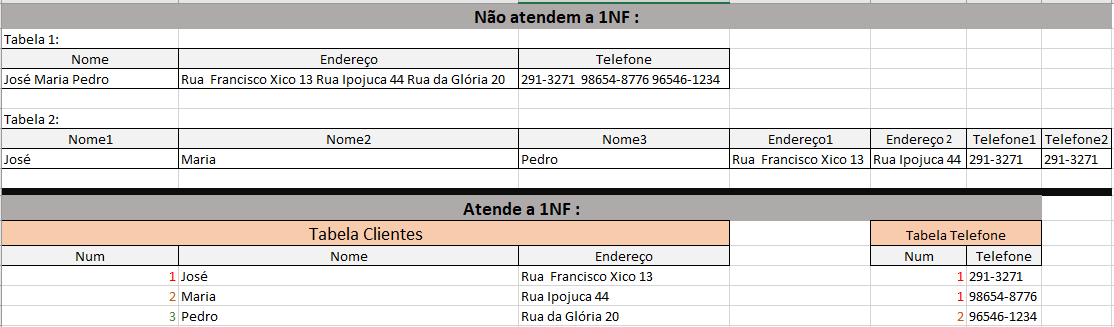
Notas :
1-Um cliente normalmente tem apenas um endereço de moradia. No exemplo estamos armazenando apenas o endereço de moradia. Contudo poderíamos querer armazenar o endereço de moradia, trabalho, estudo, etc e aí teríamos que mover o campo endereço para a tabela endereços.
2-Como dito acima quando dizemos que só estamos armazenando o endereço de moradia podemos dizer que o cliente em relação ao endereço de moradia tem uma cardinalidade de 1 para 1, contudo muitos clientes tem mais de um telefone de contato, portanto é correto assumir por causa dessa 'possiblidade' que a cardinalidade de cliente para telefone é de 1 para N ( N porque não sei quantos são) .
Normalização - Segunda regra Formal - 2NF
A primeira coisa a notar é que a primeira regra formal deverá ser atendida para poder atender a segunda.
A segunda norma formal define que o valor do campo em sí não deve ter valores repetidos.
Por exemplo, tenho uma tabela de vendas e um cliente aparece 100 vezes comprando 100 produtos. Não seria melhor criar uma tabela clientes, mover o nome do cliente para essa tabela criando uma relação, por exemplo, com uma chave primária (primary key) ? Com certeza. Se houvesse um erro na grafia do nome do cliente teríamos que corrigir em 1 registro apenas e não em 100.
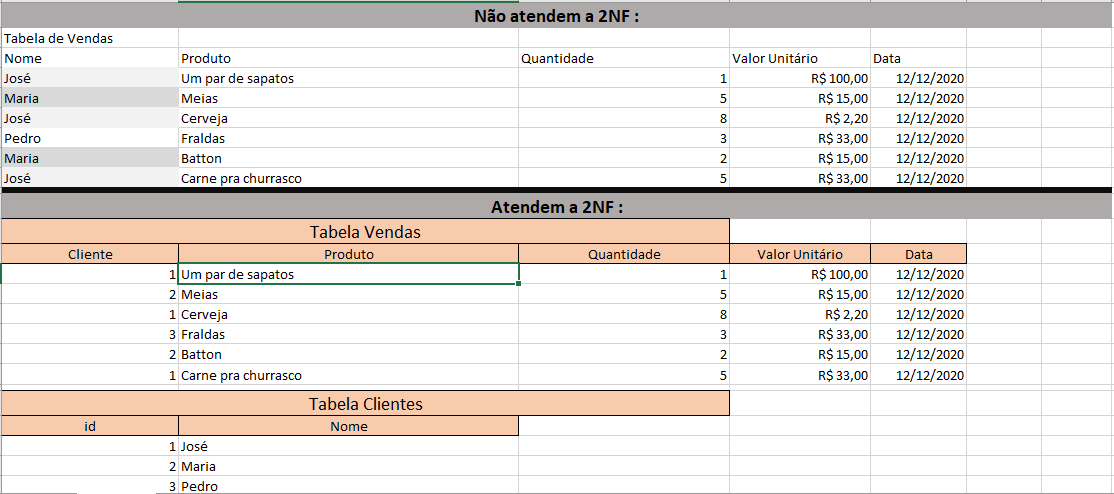
Esta regra visa economizar espaço ocupado no campo e consequentemente no disco e mesmo diminuir a banda de rede ocupado numa pesquisa porque retornar 100 vezes um nome com certeza é muito maior que 100 vezes o mesmo número.
Normalização - Terceira regra Formal - 3NF
Esta regra visa estabelecer que o campo realmente pertence a entidade do dado. Como disse acima, telefone, endereço são dados de um cliente mas não pertencem em sí e obrigatóriamente a um cliente, posso ter dois clientes morando na mesma rua, por exemplo.
Um exemplo clássico de uma tabela que não cumpre esta norma é quando armazenamos o endereço na tabela de clientes. Como podemos ter mais de um cliente no mesmo endereço ( só o número seria diferente ) faz com que o atributo endereço não seja 'único' para o cliente e para atender esta regra ele deveria estar armazenado em uma 'entidade' (tabela) diferente.
Normalização - Quarta regra Formal - 4NF
Esta regra visa definir que chaves primárias compostas sejam realmente únicas. Cada campo agrupado na chave é realmente necessário para fazer a pesquisa.
Uma chave primária composta, por definição, é composta por mais de um atributo (colunas). Contudo ao efetuar uma pesquisa com um atributo a menos dessa 'chave primária' o resultado trazido seria exatamente o mesmo, funcionaria perfeitamente da mesma maneira, com a mesma cardinalidade, dizemos que a tabela NÃO cumpre a 4NF. É uma redundância na chave primária e isto é um custo para o banco de dados.
Normalização - Xa regra Formal - XNF
Existem muitas outras regras de normalização que combatem o desenho pobre de um banco de dados. Contudo são muito mais específicas e pegam detalhes que só num datawarehouse ou datamart implicariam em perdas relevantes. Se você é um DBA especializado em 'fine-tunning' deverá conhecê-las. Senão, faça uma pesquisa e leia sobre o assunto. Saiba que elas existem mas o campo de aplicação é bem menor e mais específico.